本文最后更新于 1 年前,文中所描述的信息可能已发生改变。
声明:本文不是软件开发教程,并不会教您开发「某狗输入法」「某度输入法」之类的输入法软件。本文不涉及程序代码,仅起思路上的抛砖引玉之用,欢迎各位输入法先达指教。
如果您从未接触过字形输入法,可先阅读北鸮的这两篇文章:尝试了七种形码输入法后,我想聊聊在 2022 年用五笔这件事、为了打字更爽,我学了一个追求极致性能的小众输入法。本文前言也作了简短介绍,仍有不懂可留言,我会再补充。
关于本人:聊天打字用星空键道,书面打字用三徐(自用徐码改版),打单速度 60 字每分钟。之前浅学过小鹤音形、仓颉五代和虎码,因需求不同而放弃。
前言
汉字输入法的定义
其实很简单:输入编码,输出汉字集合的函数就是汉字输入法。
假设 为 个汉字的集合, 是 个 子集的集合, 是 的第 个元素, 为 个编码的集合, 即输入法。
如今简化字使用区大部分人用的都是汉语拼音输入法——输入汉语拼音,输出汉字;少部分人使用五笔字型输入法——输入由 A 到 Y 组成、长度小于四的编码,输出汉字。
在传统汉字使用区,还有仓颉输入法——输入由字母组成、长度小于五的编码,输出汉字;注音输入法——输入由键盘上绝大多数字符组成的编码,输出汉字。
实际上,使用 Unicode 编码打字也能算是一种输入法。
字形输入法与字音输入法
上文提到的汉语拼音、注音属于使用汉字读音进行编码的字音输入法(以下简称音码);五笔、仓颉属于使用汉字字形进行编码的字形输入法(以下简称形码);小鹤音形的编码方式先用字音再用字形,所以属于音形码。
如今,虽然搭载大词库的音码已经能满足日常交流的打字需求,形码因其重码低且不依赖读音的特点仍具使用价值,故爱好者还在不断研发新的形码。
字根与拆分
字根
字根是形码拆字的基本形状单位。 其与我们小学时学的偏旁、部首等概念相似,但字根的范围往往大于偏旁、部首。
比如 86 版五笔输入法共有 234 个字根,其中「王」「土」「日」都是我们熟悉的偏旁,而「炙」的上半部分、「互」的中间部分就显得有些陌生了。
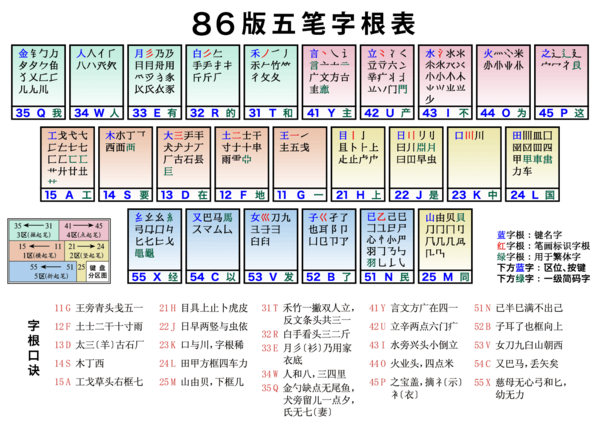
在一些形码中,结构复杂的汉字也可能设为字根以减轻用户拆字负担,比如徐码里「爾」「鹵」「黽」都是字根。
拆字
拆字即使用已设置的字根拆分汉字。这其实也是我们小学就经历过的内容——在学习生字时,语文老师会教我们它是由以前学过的字组成的。
如何拆分结构简单的字,大家应该没什么意见:「叶」自然是拆成「口」和「十」,「音」自然是拆成「立」和「日」。但如果字的结构稍微复杂一点就难办了:「戊」是拆「戈丿」,还是拆「厂㇂丿丶」呢?这时候就要引入限制拆分方式的规则,防止一个汉字出现多种拆分。
还是拿 86 五笔举例:五笔中按优先级有兼顾直观、符合笔顺、取大优先、能连不交、能散不连这么几条规则。
先从取大优先、符合笔顺讲起:
- 「世」可拆「一凵𠃊」和「廿𠃊」,因为后者的第一个字根比前者的第一个字根大,故拆「廿𠃊」。
- 「夷」能拆「一弓人」和「大弓」,但因为「大弓」拆法不合笔顺且合笔顺优于取大,故拆「一弓人」。

能散不连、能连不交就是字面上的意思,字根不相连的拆法优于字根相连的拆法,字根相连的拆法优于字根相交的拆法。有的输入法还会引入更进一步的能交不断,指字根相连交的拆法优于同一笔画断开的拆法。这三个规则合称散连交断。
兼顾直观则比较难懂,它在五笔中已经成为一种万能规则,即作者主动认定什么拆法直观。比如下图的「或」「戊」两字,前者能不合笔顺拆「戈口一」,后者却得合笔顺拆「厂㇂丿丶」。而在 86 五笔之中,这样的问题比比皆是:为什么「里」拆「日土」不拆「甲二」?为什么「匹」拆「匚儿」不拆「兀𠃊」?

这种模糊不清的规则是万万要不得的,如今建议使用更清晰有理的规则。比如「匹」的拆分规则就可以用引入结构完整(「囗日目勹冂匚コ凵」等存在全包围和半包围结构的字根不拆散)来解释。另外,还可引入原形字根(如果一个字根的的竖笔在作偏旁时变作撇,或横笔在作偏旁时变作提,视其为优先级更低的变形字根)规则,也可解释一些拆分歧义。
不过拆分规则并不是越细越好,像张码为了降重把规则搞得十分复杂,为难的也是用户;仓颉的拆分方式更是码圈独树一帜。输入法作者应在保证拆分唯一性的前提下制定最易理解的规则,以减轻用户的心智负担。
 仓颉拆分一观,截自维基仓颉教科书
仓颉拆分一观,截自维基仓颉教科书
在拆完常用 3500 字(通用规范汉字表一级字)后,我们便得到了一张可用的拆分表。
增删字根
五笔的作者王永民先生曾说过:「一般来说,一个使用 26 键的拼形方案,以选取 150~250 个字根为宜。」,现在大多数新输入法的字根归并后也属于此范畴,符合统计学原理。
在四码方案中,参与单字编码的根数往往只有前三根和最末根,可以说中间这些字根实际上没有用处。如果一个字根从来没有参与过编码,当然可以直接删除此根;如果有多个字的前三末一字根都相同,如「赢嬴贏」,就要考虑增加字根以取到不同的根,将重码扼杀在拆分这一步。
如果你想了解在拆分阶段进行定量分析的更多理论依据,可参考蓝落萧的文章拆分表的定量评价。
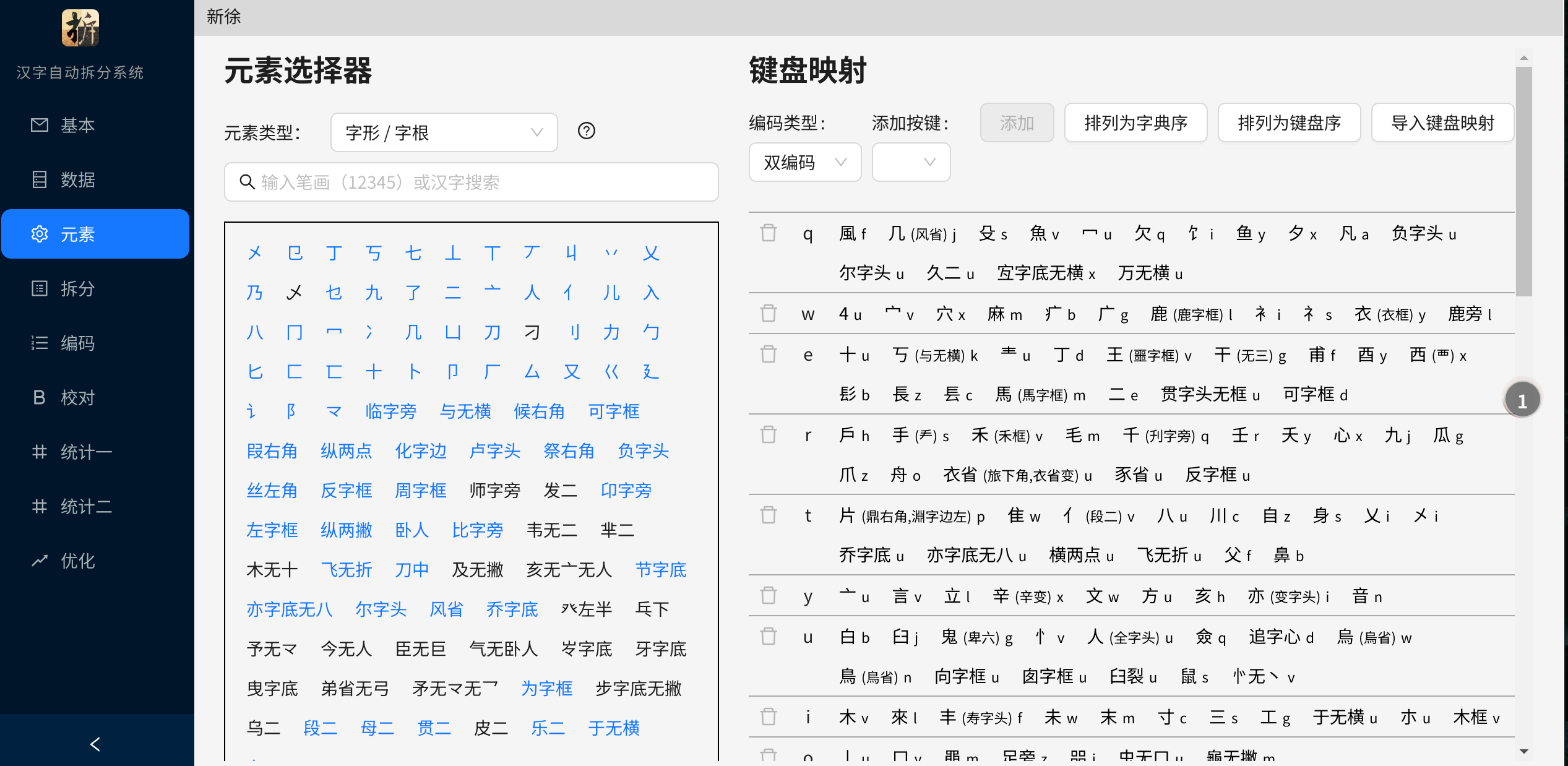
在这里也帮蓝落萧打个广告:如果你对制作形码有兴趣,看到此处仍不得要领,请考虑使用由蓝落萧主持开发的汉字自动拆分系统(请无视注册功能,选择示例即可进入主界面),全 UI 操作没有门槛。
编码方式
字根编码
对字根进行编码,是对单字编码的前提。字根编码一般会有一定规律,比如五笔用首两笔在 QWERTY 键盘上分区,郑码用首两笔对应字母序,仓颉用「日月金木水火土」对应字母序,表形码用字根的形状对应字母,这些用字形特征对字根进行规律编码的方式称为形托。正如有音码形码,字根编码也有音托形托,小鹤音形就是采用音托。
也有输入法为了更好的性能指标,会使用完全无规律(下称乱序)的方式编码字根,比如蓝宝石输入法。
字根的编码方式多种多样,以下直接列举:
- 单编码,以五笔为代表,每个字根用一个字母表示,比如「十二」的编码都是 F,「五一」的编码都是 G。
- 双编码,绝大多数字根两个字母表示,分别称大码、小码。
- 小码形托,以郑码为代表,小码与汉字的字形有关,比如「耳」的小码为 E,因为其结构中包含「十」。
- 小码音托,小码与汉字的读音有关,比如徐码中「自」的小码为 Z,因为其汉语拼音为 zi。采用音托可减轻记忆量,使双编码字根的记忆难度无限逼近于单编码。
- 三编码以上……事实上想要字根编码多长都行,但如果用户连字根的编码都记不住,更别提之后的单字编码。
单字编码
首先自然要决定一个字有多少字根参与编码,本文采用主流形码的取法,即前面提到的前三末一。字根不足四个怎么办?就要用汉字的其他字形特征进行补码,在五笔中是字根笔画或汉字结构,在郑码中是字根的小码;当然也可以用汉字的读音补码,不过那样就成形音码了。
比如像「呗员」「吧邑」这种两个字根一模一样的字,我们就需要使用结构码来区分,上下结构补 B,左右结构补 N。但结构码的引入又给用户造成新的记忆点,这时双编字根就可以派上用场——可以在使用频率较小的字的编码后补上首字根的小码,这样二者的编码也能分离。
假设一个汉字可以被拆分为若干字根,每个字根都有一个编码,那么该编码用大写拉丁字母 ABCD…WXYZ 编号。特别地,Y和Z用来强调倒数第二、第一根。表示字根笔画,使用小写希腊字母αβ…ω。特别地,ω用来强调倒数第一笔画。Ω 表示字形结构编码。
则五笔的编码表式为:
- 单根字
- 代表字根 AAAA
- 非代表字根 Aαβω
- 多根字
- 两根字 AZΩ
- 三根字 ABZΩ
- 四根及以上字 ABCZ
如果你想了解更多输入法的编码方式,可参考朱宇浩的文章常见形码输入方案编码规则。
词语编码(可选)
如果你不想只打单字,词语编码就必不可少。好在输入法界目前有公认的词语编码方式,无需费任何脑筋思考新方式。就像字根组成单字一样,单字组成词语,所以词语的取码方式和单字类似:
每个字都有一个编码,那么该编码用大写拉丁字母 ABCD…WXYZ 编号。特别地,Y和Z用来强调倒数第二、第一根。字的第二编码用对应的小写拉丁字母abcd…wxyz 编号。
则形码的词语编码表式为:
- 两字 AaBb
- 三字词 ABCc
- 四字及以上词 ABCZ
性能调优
性能指标
坊间还流传着五笔作者王永民先生的另一句话:「一个高水平的 “形码” 方案,必须同时具备以上相容、规律、谐调这三个特性。」所谓相容,即重码低;所谓规律,即易学;所谓谐调,即手感好——这三者不可兼得。很多时候,输入法是放弃了一项优势来换取另一项优势,比如现在赛文流行的乱序输入法(虎码、蓝宝石、逸码)就是放弃了规律来提升其他两者,而我使用的徐码很大程度上放弃了谐调以迫求大字集的相容。
- 静态重码数:遍历所有编码,每次输出的汉字集合大小为二的子集数总和,反映相容性。
- 动态重码率:输出的汉字集合按字频排序,移除第一个元素,剩下的元素字频的总和,反映相容性。
- 平均码长:编码长度乘以汉字的字频的总和,注意非首选字的编码长度加一,与动态重码率正相关。每分钟输入字数 = 每分钟击键数 / 平均码长。
- 速度当量:从二百多万个实验数据中统计分析的连续键位舒适度,详细请参考论文键位相关速度当量的研究,反映谐调性。
- 双手互击率:输入所有左右手交替击键的编码,输出字集内字频的总和,反映谐调性。
还记前言里对输入法的数学定义吗?我们可以由此推出以上指标的数学定义。
假定 为汉字在某文本状态下的单字频率的映射,用字频对 中的每一字集排序,使 是编码为是编码为 的第 个汉字,, , 且满足 时,.
- 静态重码数:
- 动态重码率:
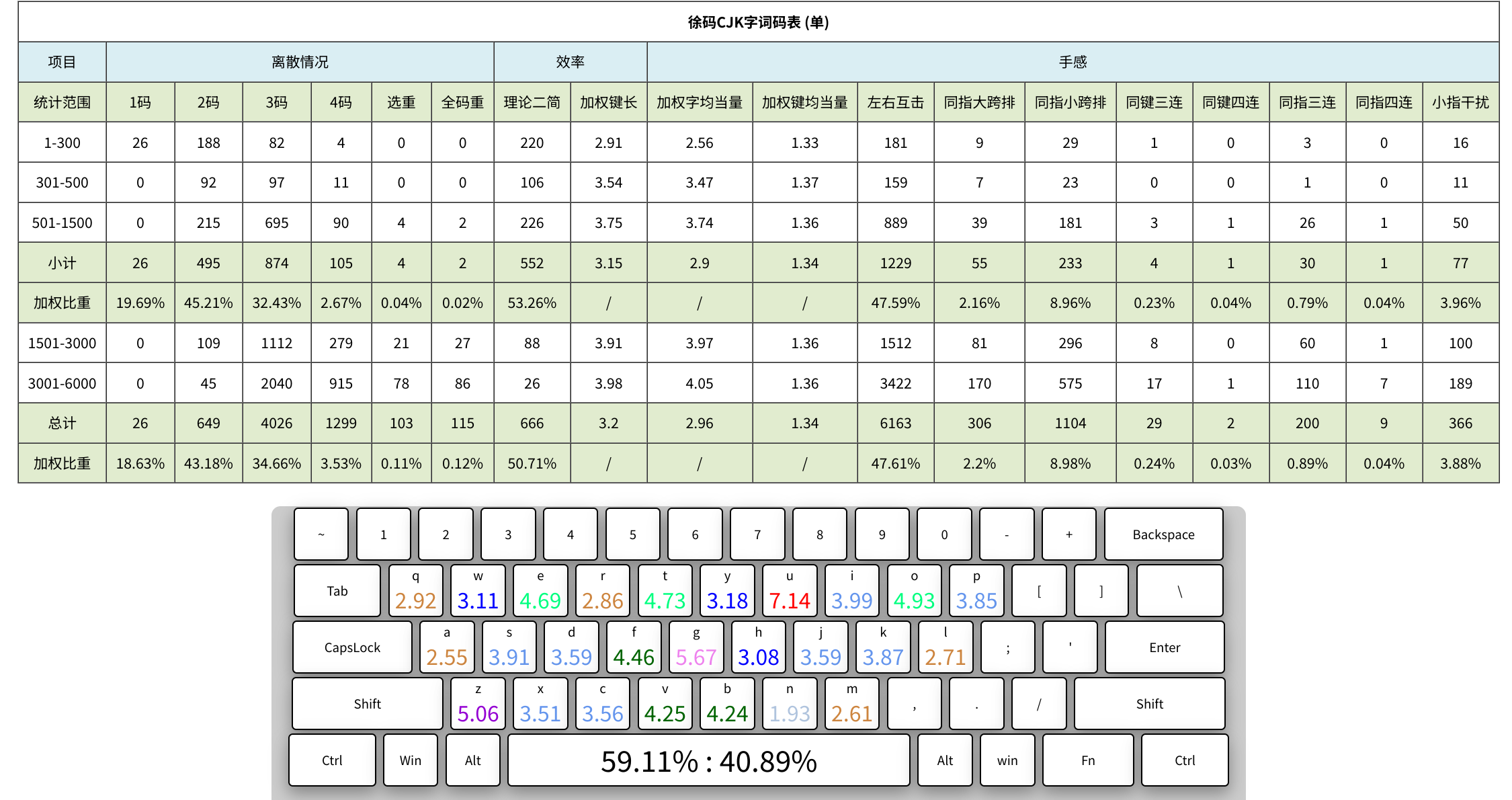
如果不懂得计算这些性能指标,也可用在线的虎码测评网。
出简让全
五笔的单字编码和词语编码的长度都大于三,这是因为其在设计编码规则时就为简码留下空间。简码即更简短的编码——「的」字的五笔编码为 rqyy,但实际只要打 r 再按下空格就能上屏「的」。像「的」这种只保留前一码的简码称作一级简码(简称一简),以此类推则有二简、三简。
简码是提高输入效率最简单的方法。常用前 26 字的频率总和为 0.26,如果所有单字的编码都是四码,刚好出满一简即可减短 0.5 的平均码长;常用前 27-702 字的频率总和为 0.57,也就是说出满一二简可减短 1.09 的平均码长。而我们知道打字速度=击键次数/码长,所以理想状态下出满一二简,打字速度提升了三分之一。
而出简的好处远不止如此。与简码相对,单字原来的编码称作全码。既然该全码码位上频率最高的字已经出简,字频排第二的字自然可以顶上,这种做法称作让全,即让出已有简码的字的全码码位。这样一来便能消除原有的重码,即使三简没有码长上的收益,也能用来降低重码。
好处这么多,代价是什么?简码实际上是一种无理码,出得越多用户的记忆负担就越重。一旦记不住就要浪费时间看候选框,反而降低击键数,得不偿失。建议只出一简,二简交给用户自己设置或只出简不让全,别设三简。
全局优化
全局优化一般使用模拟退火算法,程序请参考模拟退火算法原理及应用、输入法优化、字频、词频统计算法源程序分享、宇浩输入法开发技术文档,本文不再多说。
由于退火算法的原理就是撞概率,所以设置一些约束条件(如不能在同一键位的字根与必在同一键位的字根)可以有效减少无用字根排布,进而提升算法效率。在设置约束条件可以多采纳前辈的智慧,举个例子:在设计三徐之前我一直很好奇,为什么规律双编形码总要在一个大码下要设置两个小码固定不规律的主根?后来自己着手优化后才发现,如果不出两个主根重码必然提高。
尾声
在你的输入法大成之时,别忘了导出码表供爱好者们使用:大多数输入平台支持的码表格式为每行 字\tab编码,也有少数输入平台是倒过来。如果对自己的输入法有自信,可到五笔吧发帖宣传。输入法离不开社区的支持,有了用户便可以根据反馈调优,使输入法更加完美。
当然,密码学有句老话叫「不要自己设计加密算法」,我认为输入法亦是如此。真要设计之前,不妨先找一下市面上有没有适合自己需求的输入法,用现成的总是比较简单。
闲话:选择输入法的哲学
目前 Unicode 汉字收录约十万,也就是说电子设备装上字体后能显示十万汉字,预计今后还会不断增多(CJK-J 区新收录四千多字)。这些汉字中,并不是所有汉字的读音都流传到了现在;还有部分字虽有读音,但不去查字典基本不知道怎么读——要打出这些字,就必须使用形码。综上所述,大字集重要吗?还是不重要。就算你的名字中有生僻字,加这个字到码表上就行了,没必要寻找能打全字集的输入法。就我个人而言,拆大字集是作为汉字爱好者的乐趣,并不是什么刚需。
打字速度重要吗?当然重要,但要想想自己有没有毅力练习。打字速度的木桶效应十分明显,而输入法性能其实是其中最长的一板。想要提高跟打速度,不管你用什么输入法,唯有长时间的练习才能做到。不要想着选了性能最好的输入法就万事大吉,速度高手不是因为选择了更好的输入法而成为高手,而是速度高手为了更进一步发明了更好的输入法。如果你连非水文生稿单字百速都达不到,谈何输入法性能?
簡繁通打重要吗?當然不重要,小衆需求中的小衆需求。主要還是 OpenCC 轉換有所不足,有些異體字沒必要轉換:比如「羣」,我一直認為左右結构的「群」在電子設备上顯示效果更好。
说到底形码重要吗?其实也不重要。双拼学习成本低,降低全拼码长却是立杆见影。输入法是为了输入文字而存在,文字所承载的知识才是人类通天的阶梯。